Redis如何优化如何好用?
前言
首先Redis为什么这么快的说法必须要有一个前提才能站得住脚
因此本文更希望去讨论,Redis如何优化到目前这个性能以及为什么我们经常使用它
上下比对
回顾八股
比对之前我们先看看日常八股中提到的
- Redis是基于内存操作
- Redis高效数据结构,对数据的操作也比较简单
- Redis是单线程模型,从而避开了多线程中上下文频繁切换的操作
- 使用多路I/O复用模型,非阻塞I/O
首先八股就很有意思,直接不谈任何上下文,只是罗列了一堆技术应用
基于内存就很快?那我们何不直接使用MySQL 的 Memory 引擎?
单线程模型——》避免多线程上下文切换开销,那朋友们写代码的时候一定狠狠遵守单线程模型的吧
多路I/O复用模型,目前开源的优秀组件,大多数都有多路I/O复用
高效数据结构,这没得喷,这个是真神
本地缓存
很多时候我们会采用本地缓存 + Redis缓存 + DB
显然本地缓存速度是更优于Redis的
他们的差异点主要在于
- 本地缓存无网络通信开销
- 无需序列化转换
Redis如何向上对齐?
网络通信优化
网络通信这一点极为关键,虽然拖慢了速度,但也是让Redis作为缓存、分布式锁、队列的关键点,能作为分布式系统的 关键中转点
既然做不到直接将网络通信优化,那我们可以考虑将网络通信开销优化😊
- Redis 采用RESP 文本协议(不同于HTTP)一种简洁的文本协议
- Redis 实现Pipeline,把多个命令“打包”一起发送,减少 RTT(类比HTTP1.1优化HTTP1.0)
序列化优化
本地缓存 Java类存储到Java类,取出同理
Redis则是 从Java类——》Redis——》Java类
不同应用的数据传输需要通过序列化以及反序列化操作
那Redis也需要从序列化的优化上做手脚
但其实使用Redis时,序列化方式往往是我们自己选择的
它本身操作的是字节数组或字符串,相比较于JSON这种可读性序列化来说
速度是大大滴快的
MySQL&&MySQL Memory
前面八股说到,Redis基于内存操作,所以快
可是MySQL Memory也是内存操作啊,这样为什么还要引入Redis?
Redis向下借鉴
数据结构的优化&转换
Redis单线程执行命令的好处,无需像MySQL那样还需要MVCC、表锁、行锁
更重要的是MySQL memory索引使用B+树索引或hash索引
Redis采用多种数据结构应对不同的使用场景
- 字符串——SDS字符串(优化C语言的字符串数组)
- List —— 压缩列表/双向链表(高版本紧凑列表更新为quicklist)
- Set —— 整数集合/哈希
- Zset —— 压缩列表/跳表 (后续更新为quicklist)
- Hash —— 压缩列表/哈希表(后续替代为listpack)
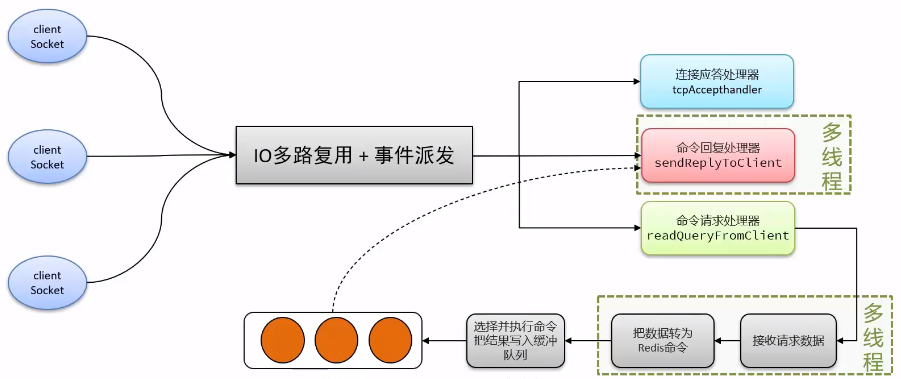
单Reactor单线程-》单Reactor多线程
Reactor核心
- 三类处理事件,即连接事件、写事件、读事件;
- 三个关键角色,即 reactor、acceptor、handler。
在Redis6.0后,引入多线程网络I/O用来 处理网络请求以及响应,但执行命令的核心流程仍然是单线程执行
根据自身适用场景优化同行
| 方面 | Redis | Netty |
|---|---|---|
| I/O 多路复用 | 基于 epoll,主线程直接轮询处理所有事件 |
Reactor 模型,bossGroup 负责接收,workerGroup 处理 |
| 并发模型 | 完全单线程(I/O + 命令 + 内存全部串行处理) | 多线程,任务在多个 EventLoop 间调度 |
| 命令执行模型 | 命令直接在主线程中调用对应 commandTable 执行 |
业务逻辑需要开发者实现处理器,挂载在 ChannelPipeline 上 |
| 线程上下文切换 | 无 | 有(尤其是 channelHandler 切换线程执行) |