MySQL SQL调优实战
后续把我的ArchLinux docker证书弄好,再考虑Es,Windows感觉太不方便了还是
文章暂时也不会很详细针对const、ref、range去进行优化,一般达到range已经完全足够了
表结构
商品表:product id (int , pk) name (varchar ) category_id (int ) price (decimal ) status (tinyint) create_time (datetime) 商品详情表:product_detail id (int , pk) product_id (int , fk) description (text) sales_volume (int )
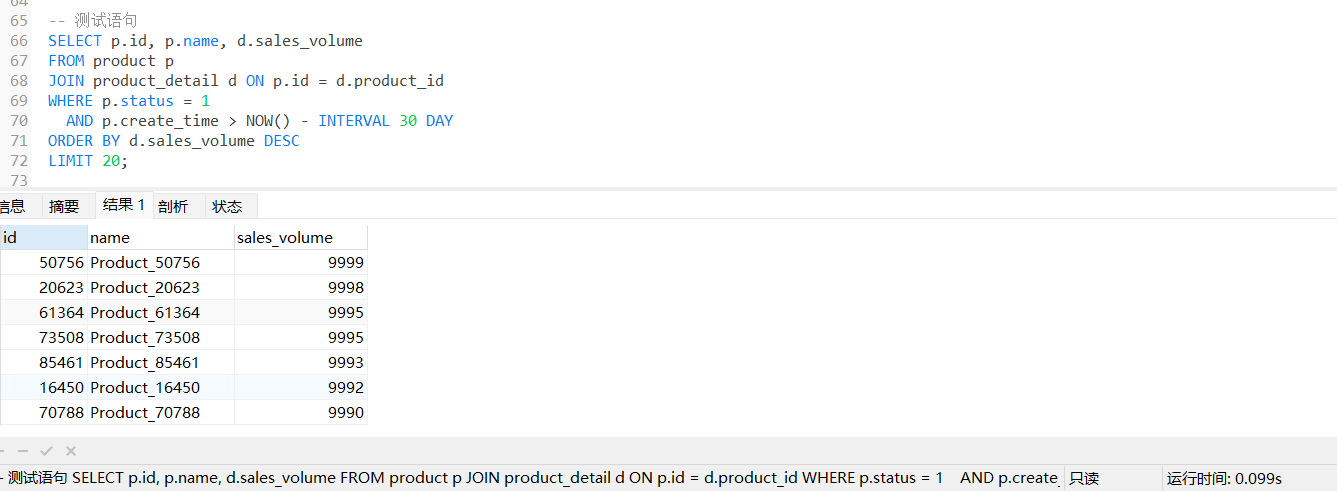
用户希望在商品页中加载「最近一个月内上架的、销量前20的商品」并按分类聚合。
初始化表&mock数据 DROP TABLE IF EXISTS product;CREATE TABLE product ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR (50 ), category_id INT , price DECIMAL (10 ,2 ), status TINYINT, create_time DATETIME ); DROP TABLE IF EXISTS product_detail;CREATE TABLE product_detail ( id INT PRIMARY KEY AUTO_INCREMENT, product_id INT , description TEXT, sales_volume INT , FOREIGN KEY (product_id) REFERENCES product(id) ); DELIMITER / / DROP PROCEDURE IF EXISTS generate_data / / CREATE PROCEDURE generate_data()BEGIN DECLARE i INT DEFAULT 1 ; DECLARE recent_days INT ; WHILE i <= 100000 DO SET recent_days = FLOOR (RAND() * 365 ); INSERT INTO product ( name, category_id, price, status, create_time ) VALUES ( CONCAT('Product_' , i), FLOOR (1 + RAND() * 20 ), ROUND(RAND() * 1000 , 2 ), IF(RAND() > 0.1 , 1 , 0 ), NOW() - INTERVAL recent_days DAY ); INSERT INTO product_detail ( product_id, description, sales_volume ) VALUES ( LAST_INSERT_ID(), CONCAT('Description of product ' , i), FLOOR (RAND() * 10000 ) ); SET i = i + 1 ; END WHILE; END ;/ / DELIMITER ; CALL generate_data();
索引优化
后续稳定到0.07s左右(buffer pool
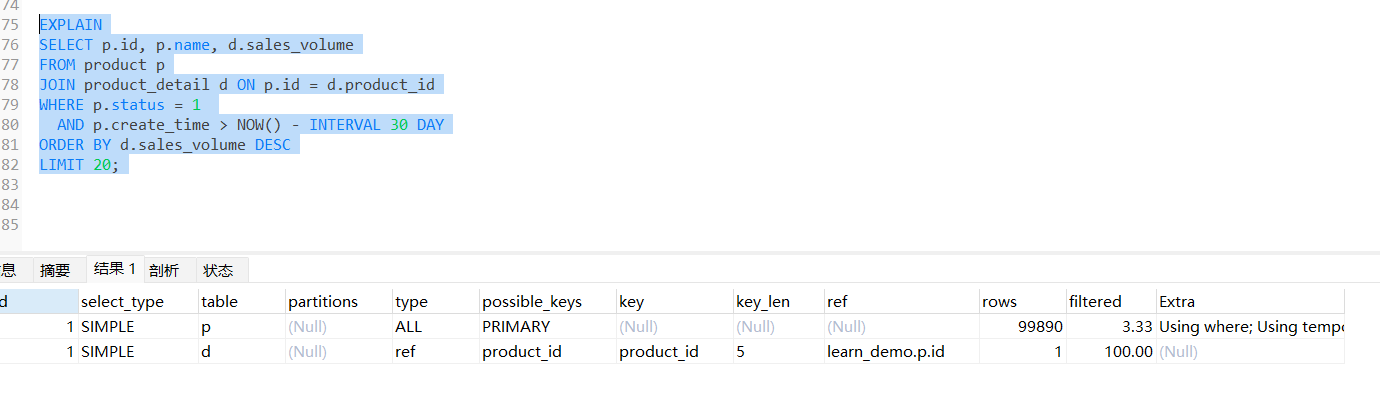
当然了,我们没有添加索引,直接就是全表扫描(type=ALL
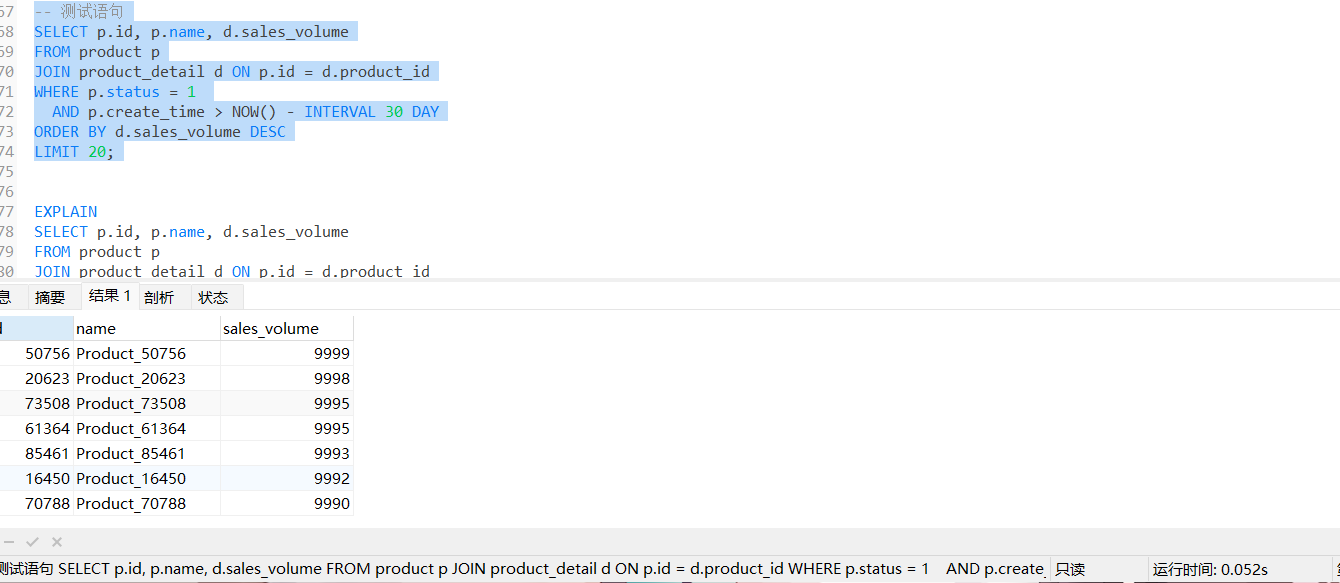
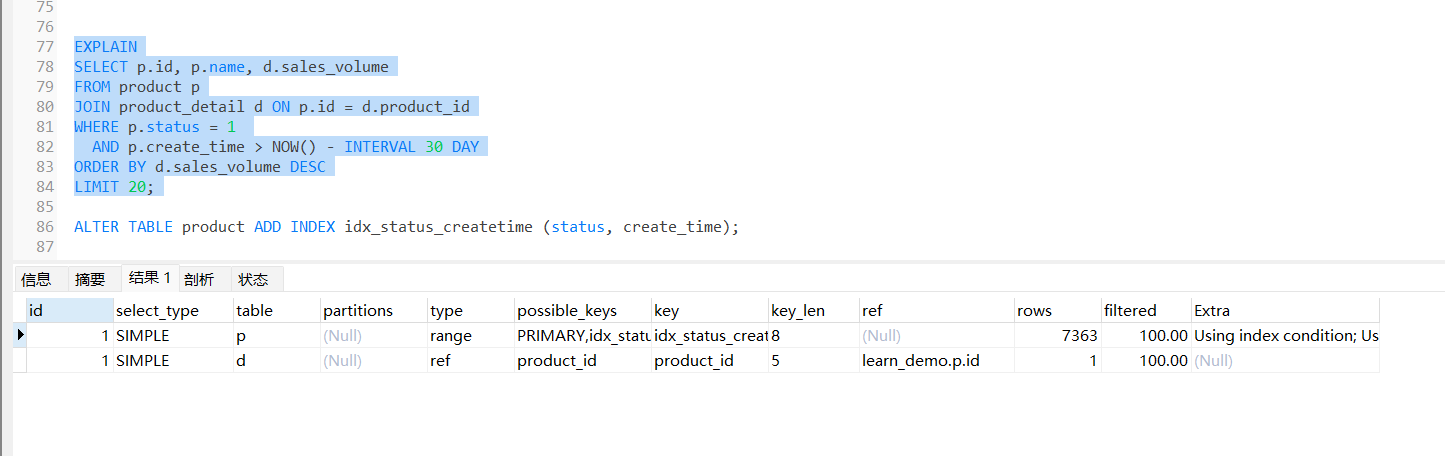
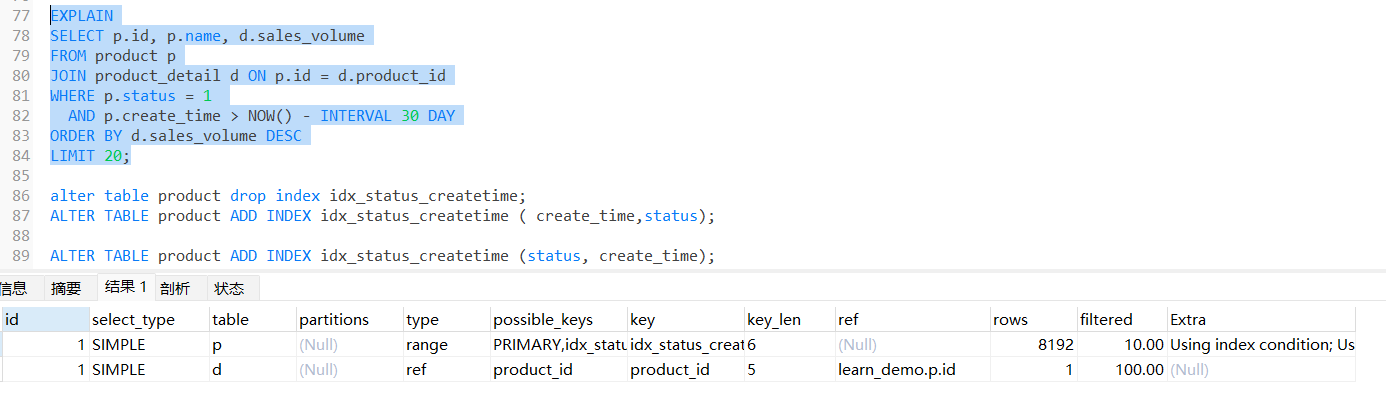
高效索引 ALTER TABLE product ADD INDEX idx_status_createtime (status, create_time);这里首先 status 一般是恒等的,因为需要查询某个状态,而create_time则通常是范围查询 由于索引数据结构为B+ 树,在建立索引时,status应当放到create_time之前
建立索引后
可以看到rows大幅下降,且type也是显示range,extra 中变为using index
低效索引 alter table product drop index idx_status_createtime;ALTER TABLE product ADD INDEX idx_status_createtime ( create_time,status);
可以看到过滤率更低,且rows更高(create_time范围查询,而status=1只能在回表时进行过滤
深分页
首先我们通过触发器也是造了10w条数据
alter table product add index idx_createtime(create_time);
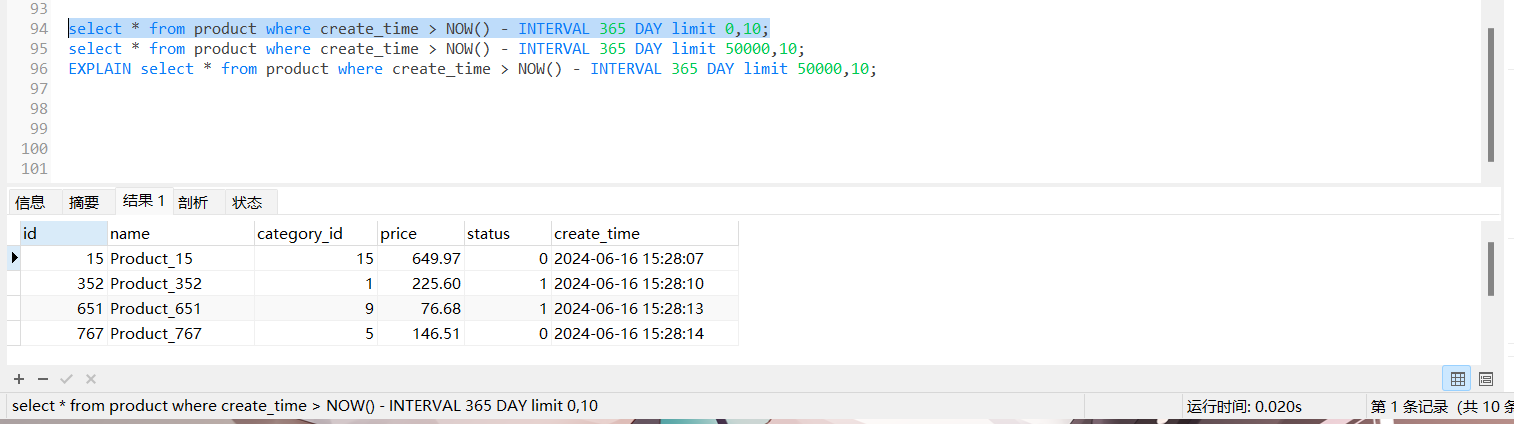
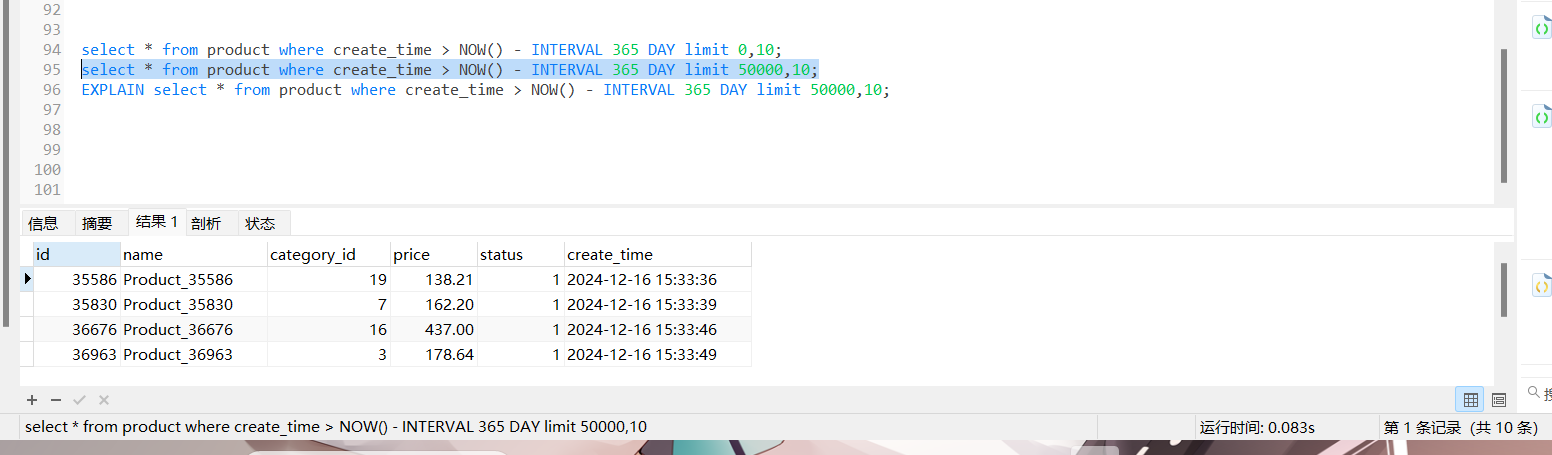
可以看到,将limit 后的0 改为50000,查询速度却差了一大截
我们走索引查询,但是由于 没有索引覆盖,会进行回表查询 但是第二个语句 第一次查询,会查询50000 + 10 条的id+ update_time 第二次查询,回表查询50000 + 10 条数据行,然后丢弃50000 条 第二次查询完完全全是浪费的,完全没必要把50000 进行回表
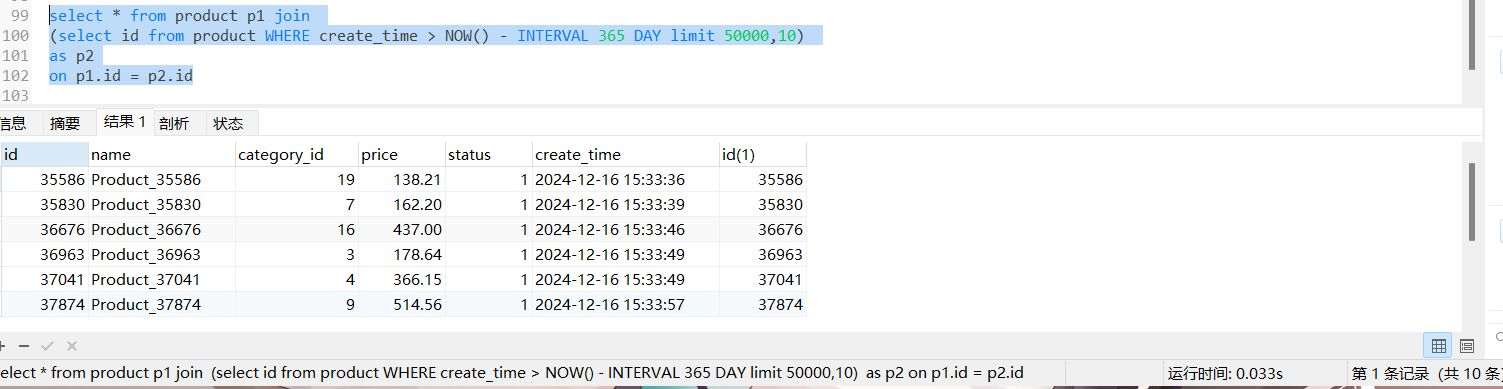
延迟关联优化 既然拖慢速度的关键是回表查询时,把无用的50000条数据也拿去筛选了
那我们不妨提前丢掉(MySQL优化器是无法直接做到的)所以需要我们自己实现逻辑
可以看到速度大大滴提高了
游标分页
需要保证id为自增的,我们记录50000条的数据id,从它后面再数10条即可
SELECT * FROM productWHERE create_time > '上一页最后时间' OR (create_time = '上一页最后时间' AND id > '上一页最后ID' ) ORDER BY create_time, idLIMIT 10 ;
索引下推
我们知道,当使用二级索引时,不满足索引覆盖则会进行回表查询
且当不符合最左匹配时,后面的属性列不会走索引,
select * from table where a > 1 and b = 1(此时b索引是失效的
设计者显然也会想到这点,比如我们要查询的数据包含了全部索引,
那我还要白白去回表查询大量完整数据行
然后在server层去条件过滤,那就太浪费了。
因此有了索引下推: 但我们查询属性包含索引列时,即使后面的索引条件失效,但是当我们通过a > 1查询到数据后,在回表查询前,会在引擎层,先用 b =1 进行一次过滤然后再进行回表查询
alter table product add index idx_price_status(price,STATUS);select * from product WHERE price > 100.0 ;EXPLAIN select * from product WHERE price > 100.0 ; select * from product WHERE price > 100.0 and status = 1 ;EXPLAIN select * from product WHERE price > 100.0 and status = 1 ;