雪花算法 ID那些事 对于Id的要求 业务
全局唯一性: 不能出现重复的id,这是最基本的要求
信息安全: 如果只是单纯的自增行为,要是有人恶意爬取分析就很难受了,经典的友商对自家商单数量分析,爬虫制定好 Url 爽爽爬取
可读性
技术
递增趋势: 由于我们常常使用MySQL这样的关系型数据库进行数据 存储,且常用的InnoDB引擎采用的B+树索引,所以主键选取上尽量采用有序的主键(不然每次insert都是一次大开销
单调递增: 保证下一个ID一定要大于上一个ID,方便进行排序、版本号等特殊需求
目前ID的使用方式 UUID
但是无序、且没有可读性,并且有另外的信息安全风险(我记得,有一个著名病毒作者就是被分析出MAC地址,然后被逮捕归案
Redis生成
通过 prefix + yyyyMMdd + sequence 这个格式生成id,其中sequence通过redis的incr命令生成
不安全
DB自增
但很不安全啊!
雪花算法
终于到文章主角了?!
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
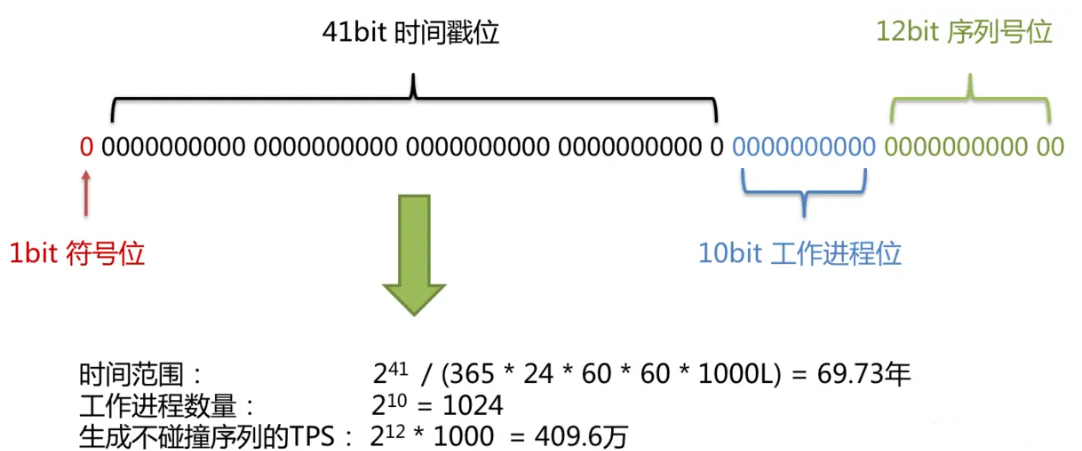
基础的雪花算法 id结构组成: 1位符号位+ 41位时间位+10位机器位+12位序列号位
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
Math.pow (2 , 41 ) / (365 * 24 * 60 * 60 * 1000 L); 复制代码
public class SnowFlake { private final static long START_STMP = 1480166465631L ; private final static long SEQUENCE_BIT = 12 ; private final static long MACHINE_BIT = 5 ; private final static long DATACENTER_BIT = 5 ; private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT); private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT); private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT); private final static long MACHINE_LEFT = SEQUENCE_BIT; private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT; private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT; private long datacenterId; private long machineId; private long sequence = 0L ; private long lastStmp = -1L ; public SnowFlake (long datacenterId, long machineId) { if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0 ) { throw new IllegalArgumentException ("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0" ); } if (machineId > MAX_MACHINE_NUM || machineId < 0 ) { throw new IllegalArgumentException ("machineId can't be greater than MAX_MACHINE_NUM or less than 0" ); } this .datacenterId = datacenterId; this .machineId = machineId; } public synchronized long nextId () { long currStmp = getNewstmp(); if (currStmp < lastStmp) { throw new RuntimeException ("Clock moved backwards. Refusing to generate id" ); } if (currStmp == lastStmp) { sequence = (sequence + 1 ) & MAX_SEQUENCE; if (sequence == 0L ) { currStmp = getNextMill(); } } else { sequence = 0L ; } lastStmp = currStmp; return (currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT | machineId << MACHINE_LEFT | sequence; } private long getNextMill () { long mill = getNewstmp(); while (mill <= lastStmp) { mill = getNewstmp(); } return mill; } private long getNewstmp () { return System.currentTimeMillis(); } public static void main (String[] args) { SnowFlake snowFlake = new SnowFlake (2 , 3 ); for (int i = 0 ; i < (1 << 12 ); i++) { System.out.println(snowFlake.nextId()); } } }
雪花算法的使用
很明显,简单场景下其实可以直接使用或者直接DB就好了
但是在企业使用下,就会有不少问题需要考虑
基础问题
机器号的唯一性
时钟回拨导致id重复
美团leaf Leaf——美团点评分布式ID生成系统 - 美团技术团队
DB + 双buffer(对于基础的DB自增的改进
Leaf-snowflake( 通过zk去协调workid以及存储时间
workid回收 现在的应用很多都是容器化部署了,每次主机的ip都会发生变化,如果在容器化中使用zk来协调workerid那么就会存在workerid很快用完的问题。
可以考虑使用workid池(活跃id以及可用id区分出来)
时间回拨问题
简单说就是时间被调整回到了之前的时间,由于雪花算法重度依赖机器的当前时间,所以一旦发生时间回拨,将有可能导致生成的 ID 可能与此前已经生成的某个 ID 重复(前提是刚好在同一毫秒生成 ID 时序列号也刚好一致),这就是雪花算法最经常讨论的问题——时间回拨
现象引发
网络时间校准(还有某些冲浪玩家喜欢修改时区
人工设置(上述中枪
负闰秒
常见解决办法 直接抛异常 还是太简单粗暴了
延迟等待 将当前线程进行阻塞一定时间,再获取时间进行大小对比,如果还是小了,再考虑抛异常
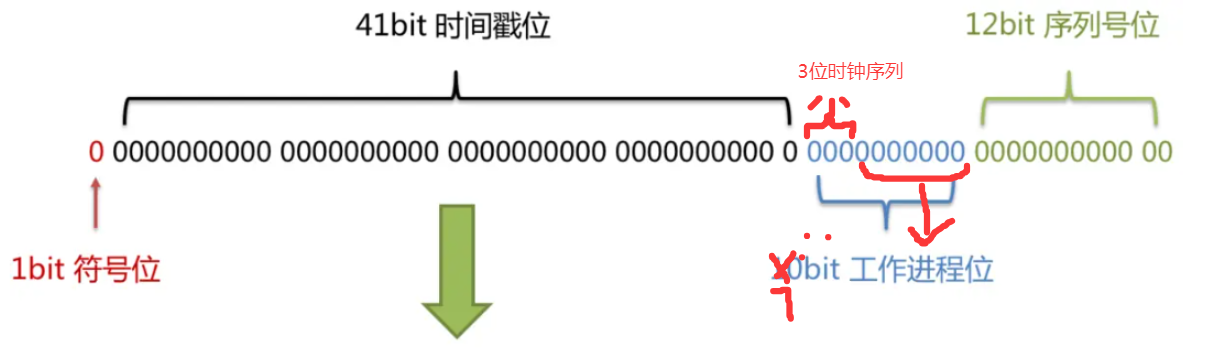
设计时钟序列解决时间回拨问题
通过修改原有 位数方案,通过扩展位解决时间回拨
将基础的64bit雪花算法进行修改
扩展出3位的时钟序列
当发生时钟回拨时,那么就将时钟序列自增1位
如果时钟序列满了,通过等待1ms然后置零
为了避免重启丢失,时钟序列也需要通过DB/文件进行存储
雪花算法,负闰秒问题
闰秒 是偶尔运用于协调世界时(UTC)的调整,经由增加或减少一秒,以消弥精确的时间(使用原子钟测量)和不精确的观测太阳时(称为UT1),之间的差异这种做法已被证明具有破坏性,特别是在二十一世纪,尤其是在依赖精确时间戳或时间关键程序控制的服务中
而雪花算法严重依赖时间戳,当出现负闰秒也就是时间减少一秒时(时间往前回拨1秒),雪花Id就可能出现重复,而原生的雪花算法出现时间回拨的处理方式是直接抛异常
2022年11月,在第27届国际计量大会上,科学家和政府代表投票决定到2035年取消闰秒