不同于之前直接使用API调用实现聊天功能
这里更希望思考以及学习AI应用开发相关原理,以及思考应用前景
AI应用开发体验以及相关思考
首先个人也是了解尚浅,网上资料貌似看上去很丰富,但是实际功能实现感觉完全没有使用大模型的意义
也许大家发布的博客或者视频内容仅仅只是展示以及入门demo
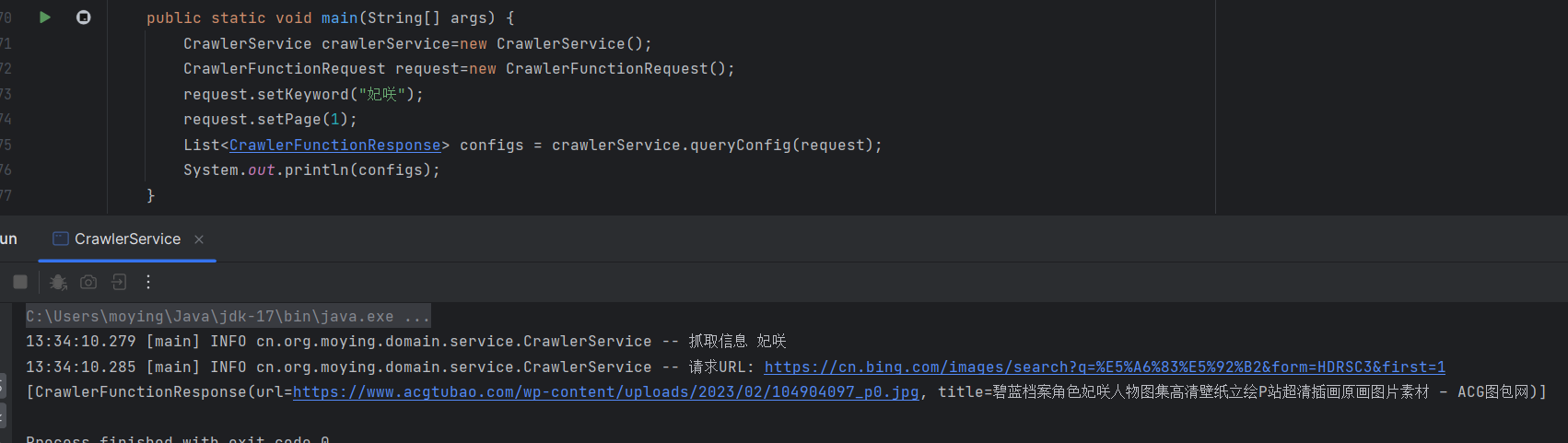
爬虫服务测试
感觉其实没什么太大问题, 但是中间细节过程发生了什么不得而知
@Slf4j @Service public class CrawlerService { @Tool(description = "根据关键词爬取图片资源") public List<CrawlerFunctionResponse> queryConfig ( CrawlerFunctionRequest request) { log.info("抓取信息 {}" , request.getKeyword()); Integer page = request.getPage(); String encodedKeyword = URLEncoder.encode(request.getKeyword(), StandardCharsets.UTF_8); String url = String.format("https://cn.bing.com/images/search?q=%s&form=HDRSC3&first=%d" ,encodedKeyword,page); log.info("请求URL: {}" , url); Document doc = null ; try { doc = Jsoup.connect(url).get(); } catch (IOException e) { throw new RuntimeException (e); } Elements html = doc.select(".iuscp.isv.smallheight" ); List<CrawlerFunctionResponse> pictures=new ArrayList <>(); Elements elements = html.select(".iusc" ); for (Element element : elements) { String m = element.attr("m" ); Map<String, Object> map = JSONUtil.toBean(m, Map.class); String murl = (String) map.get("murl" ); String title = (String) map.get("t" ); CrawlerFunctionResponse picture=new CrawlerFunctionResponse (); picture.setUrl(murl); picture.setTitle(title); pictures.add(picture); } return pictures; } public static void main (String[] args) { CrawlerService crawlerService=new CrawlerService (); CrawlerFunctionRequest request=new CrawlerFunctionRequest (); request.setKeyword("妃咲" ); request.setPage(1 ); List<CrawlerFunctionResponse> configs = crawlerService.queryConfig(request); System.out.println(configs); } }
首先本地测试没有毛病,但是在deepseek以及claude进行使用时
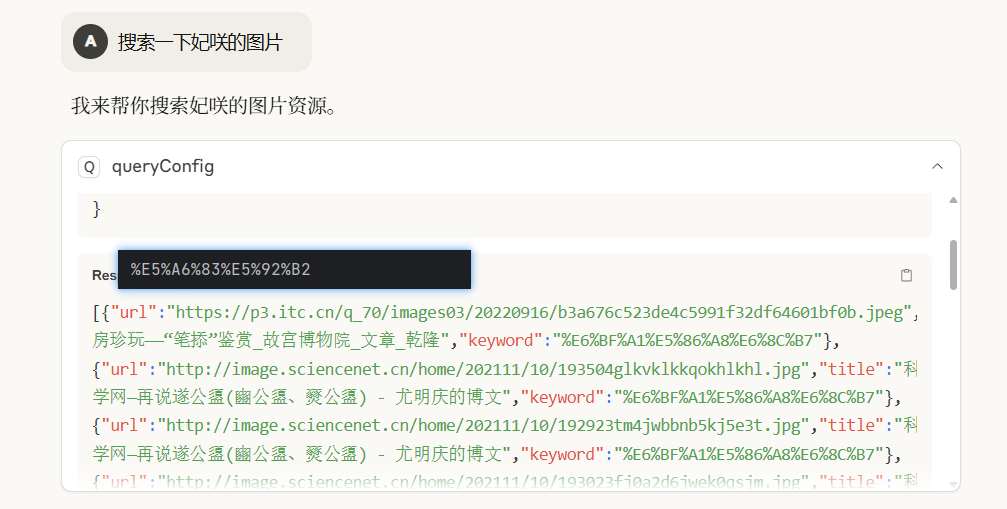
传入参数很明显有问题,
使用更加常见的关键词
将编码打印出来
很明显发现Claude使用的keyword转化后的编码不一致
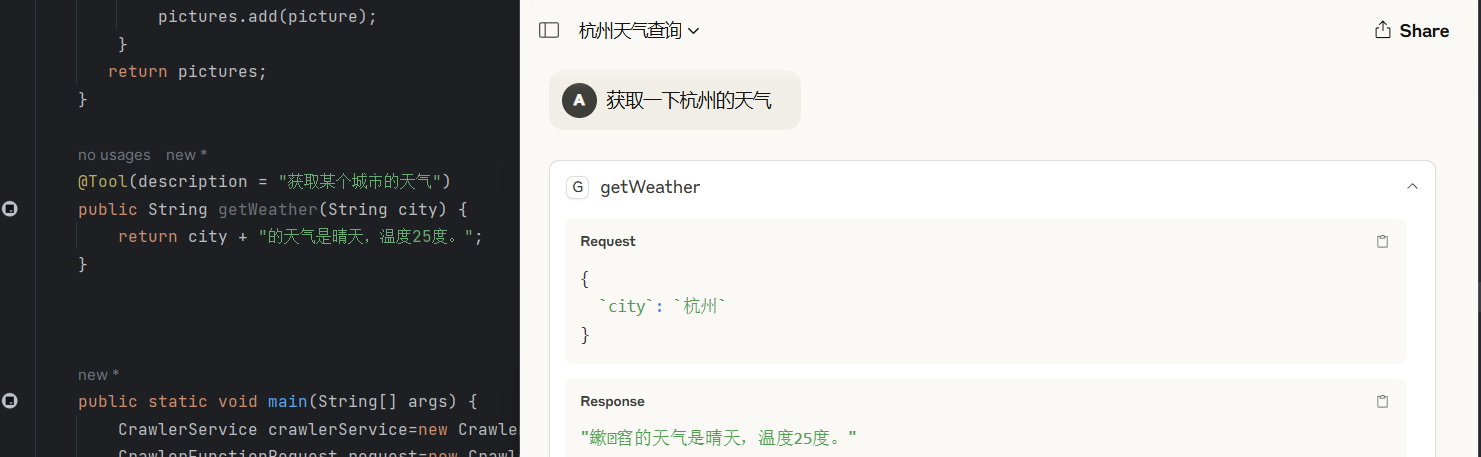
简单天气补测
解决
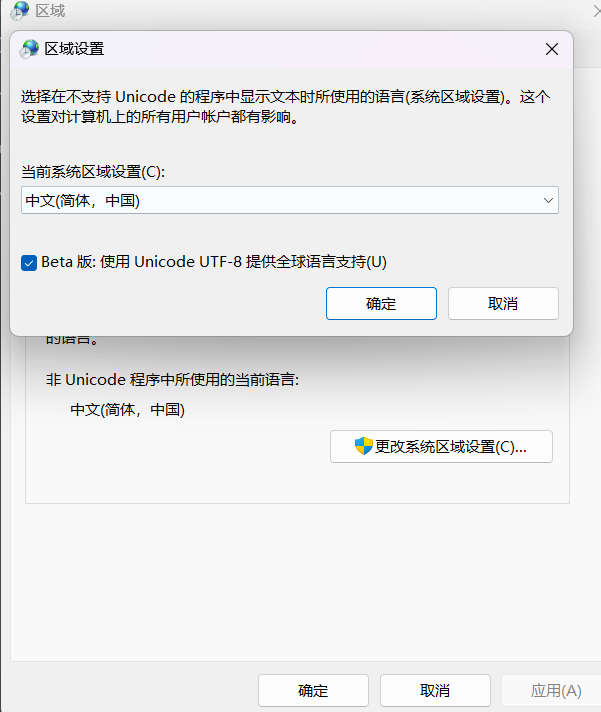
主要是Idea用多了,被惯着
应该是跟以前使用CLion以及trae同理,直接使用Java命令的话可能传入的参数虽然是中文,但是使用的是本机的GBK字符集
思考 内部运行过程
可以看到,我们从以前的直接通过前端发送问题,通过接口直接将问题传给大模型
现在加入MCP Server后,过程更加复杂
tokens使用也极为庞大!更别说还有伪记忆化功能的存在
用户请求——》前端 前端--》后端(AI Agent部分) AI Agent——》MCP Server(获取工具集 AI Agent--》将用户问题以及工具说明书给大模型 大模型选择调用哪个工具--》AI Agent AI Agent 调用工具得到结果--》大模型整理 大模型整理返回结果———》 AI Agent AI Agent返回结果--》前端展示
关于Tokens消耗
首先我们知道 大模型几乎都是伪记忆
将我们的历史对话与当前问题进行拼接,然后发送给大模型
但是这里直接调用API会发现,它并没有带有“记忆功能”
但如果我们每次都进行历史对话拼接,显然是不合理的,tokens指数级增长,且意义不大(对用户来说
Thread 功能 Overview: OpenAI Assistants API 概览
https://platform.openai.com/docs/assistants/overview
使用 Thread + Run 模式
创建一个 Thread(一次性操作)
每次添加新的用户消息,例如:你叫什么?
调用 run,OpenAI 自动从之前 Thread 的消息中构建上下文
系统会在后台使用裁剪、摘要、缓存等机制压缩内容
不再需要每次都发整段历史,只发新的一句话,OpenAI 来补全上下文 。
[ { "role" : "user" , "content" : "你好啊!" } , { "role" : "assistant" , "content" : "你好!" } , { "role" : "user" , "content" : "你叫什么?" } ]
总结 不过像是高德地图开发出来的MCP Server去让AI给我们做出旅游攻略,确实降低使用成本的话,可以极大方便我们日常生活去小红书、抖音等软件找资料
更有Google 发布的 g-mcp-server,有则能够绕过反爬虫机制的并发搜索功能,可以很好解决大模型数据资料时效性的问题,以及在搜索引擎使用较少的人来说,或者自己搜索有可能会染上网站风险,有极大利处
因此我觉得未来需要思考的便是落地方向以及成本问题。
当前的机制对于Tokens花销来说,个人开发者难以承受,若是企业接入,强如Claude接入MCP后,免费对话次数寥寥可数,更别说付费的cursor了。
如果是免费开放给用户使用,得考虑如何盈利,当然这些都是后话。