ElasticSearch 进阶
ElasticSearch

ES使用场景
- 全文搜索
- 日志检索,配合Kibana可视化
- 商品搜索
- 实时监控
- 个性化推荐,根据用户搜索历史、浏览行为找出相似内容
- 地理位置搜索(外卖系统)
- 智能提示/提示词
🔵 MySQL不能替代ES,因为:
- MySQL做全文检索很弱(like %xxx% 查询超级慢)
- MySQL不擅长复杂聚合分析(特别是大数据量)
- MySQL无法做到灵活的多字段模糊搜索、地理位置搜索、同义词处理
🔵 ES不能替代MySQL,因为:
- ES写一致性弱,不支持多表事务(比如扣库存和扣余额一起回滚)
- ES不保证强一致性(默认最终一致性,适合搜索,不适合资金类应用)
- ES的数据模型松散,复杂关系建模很痛苦(比如订单拆分、子表操作)
什么是ElasticSearch?
简单来说,ES是一个分布式的、基于文档的 搜索引擎+数据库系统
- 分布式: 天然支持分布式/集群、扩展节点
- 文档存储: 数据并不是以行或者列进行存储,而是一份份JSON文档
- 聚合分析(数值型字段)会单独存储到Doc values中,列式存储(加速聚合分析,且无冗余字段,比MySQL快太多了
- 搜索引擎: 天然支持全文检索、模糊匹配、权重排行
- 近实时: 数据写进去后,需要等待几秒才能查询到
专业术语(import)
- 集群: 一堆ES结点组成的整体
- 结点:单个ES实例
- 索引: 类似于MySQL的数据库表
- 文档: 存储的一条数据(JSON) 类似于MySQL的一行数据
- 字段(Field): 文档里面的key , 类似于MySQL的列字段
- Mapping: 字段结构定义 , 类似于MySQL的表结构
- 分片(shard):把索引数据切片到不同结点上 (分库分表)
- 副本(Replica):分片的备份
索引
ES的索引一旦建好,很多东西无法随意更改哦!
- settings中的参数能够动态修改(副本数)但是分片数无法修改
- 只能追加新字段,无法修改或者删除字段
为什么ES无法随便修改字段?
Reindex
- 创建一个新索引(新的mapping)
- 将老数据reindex过去
- 删除老索引
ES 中 就有这个API -> reindex
POST _reindex |
底层结构
- 倒排索引
极为核心的一点
不同于正排索引那样: 这个文档包含哪些字段
倒排索引描述: 这些字段 存储在哪些文档中
- 文档存储
ES中,文档时存储数据的基本单位,每个文档实际上就是一个JSON对象,包含一个唯一的ID
文档数据存储在 一个 名为 Segment 的数据结构中
- Segment(段)
ES会把文档写入到磁盘中的Segment中
每个段是不可变的(存储了倒排索引、文档存储、元数据等内容)
和LSM树的SSTable极为相似
- 倒排表
倒排表是倒排索引的存储形式,用来快速检索词和文档之间的关系
| 分词 | 文档id | |
|---|---|---|
| az | 1,2,3 | |
| 阿巴阿巴 | 3 |
- 每个词都会有一个倒排表,用于存储哪些文档包含整个词,以及这个词在文档中的位置(postings
- 倒排表会结合Posting List 来存储具体的位置信息
- FST(Finite State Transducer)
FST是ES中用来优化倒排索引的一种数据结构,用来存储词典(Term Dictionary),提高查找效率
- Term Dictionary 存储所有的term(词条)FST通过有限状态机压缩这些词条
- 由于字典中的词条数量巨大,通过压缩减少存储空间
- Posting List
用于存储某个词出现的文档ID以及其他相关信息(词频、位置等)
- 结构: Posting List 中每一项都包含了文档ID和该词在文档中的出现位置
- 索引: 每个都会有一个对应的Posting List
CRUD操作过程
关于近实时问题:https://blog.csdn.net/hugo_lei/article/details/106519069
Elasticsearch搜索引擎的索引构建过程?
- 解析文档,通过分词器将文档中的字段进行分词,存储到term dictionary中
- ES会遍历term dictionary,查看这个分词是否已经被记录过。
- 为每一个term(分词)创建一个Posting List,并将该文档id以及该词存储进去
- 如果已经为该 term 创建了一个PostingList,直接合并该文档id进去
输入一个单词去查询会发生什么?
- 由一个协调节点分析 该索引 是存储在哪个 主分片上的
- 确定好后,将该单词进行分词
- 从目标分片的Segment中使用FST 进行前缀遍历 定位 分词在倒排索引表中的偏移量
- 通过偏移量查询到该 分词所在posting list位置,然后拿到文档id集合(DocID)
- 将多个segment的id集合进行合并
- 通过相关算法计算相关性评分然后进行结果排序
- 根据from和size进行分页与截断
- 聚合分片结果(文档 ID 和评分,生成全局排序列表)获取原始文档
- 执行高亮/聚合操作 返回 JSON格式搜索结果
如何通过文档id查询到对应索引下的文档?(_id)
https://www.jianshu.com/p/0ce7d9254a80
总结: _id->确定分片->并行查询segment ->使用最新的DocId读取文档
- 通过hash 计算_id 是存储在哪个分片下的
- 在分片内定位到Segment
- 并行查询所有Segment ,若找到一个或者多个(根据版本号/时间戳选取最新的)
- Segment元信息:Segment会记录该Segment存储的 DocID 范围
- 在Segment内部查找文档
- 通过倒排索引,使用_id 查询得到DocID
- 使用DocId
- 若查询非Text 数据,仅需程序Doc Values
- 若需要查询JSON文件数据,或文本数据,需要使用正排索引拿到_source
_id字段的倒排索引缓存:_id字段的倒排索引常驻内存(如FST结构),加速_id到docId的映射。- 正排索引的懒加载: 仅当需要返回
_source或存储字段时,才访问正排索引(若只查询_id或聚合字段,可能跳过正排索引)。 - Doc Values列存: 对非
text字段,直接通过docId从列存(Doc Values)中读取值,避免解析_source。
假设查询 GET /orders/_doc/123: |
如何实现范围查询?
- 数值/日期范围:BKD树
- 字符串范围:字典序+倒排索引
- 日期范围转化为数值
写入一个新文档过程?
https://blog.csdn.net/hugo_lei/article/details/106519069
- 新写入的文档会首先暂存到in-memory-buffer中(不可被搜索到)
- 同时写入事务日志(Translog)(实时fsync写入到磁盘中,顺序写
- Refresh:默认每1秒,将内存缓冲区的数据生成新的segment并放入到文件系统缓存(可搜索)
Page Cache中? yep!
- Flush: 定期将文件系统中的段持久化到磁盘中
接下来是困难版
- 客户端发送写入请求
- 协调结点处理请求
- 解析索引名称,确定文档应该写入到哪个主分片
- 根据routing 计算目标分片位置(通过_id 进行hash计算)
- 转发请求到该分片所在主分片结点
- 主分片处理写入
- 文档先写入到in-memory-buffer中(不可被搜索、未持久化
- 写入事务日志(Translog
- 同步写入
- 顺序写入磁盘
- 返回客户端ACK
- Refresh(数据可被搜索
- Flush(30分钟/translog写满
- Segment Merge(段合并
- 后台自动执行
- 不影响搜索(旧segment在合并完成后才被替换
- 副本分片同步
- 执行主分片相同操作
wait_for_active_shards:可配置必须有多少分片可用才返回成功
删除一个文档过程
- 删除请求到达
- 不会物理删除,而是打上一个标记,同时写入到translog中(查询时会过滤
- 刷新(flush)和合并(merge)时真正删除
更新操作
本质时删除 + 新增
- 先查询旧文档打上删除标记
- 将新文档内容写入到in-memory-buffer和translog中
- 更新之后,文档的_version字段会+1,通过乐观锁保证并发一致性
- 后续通过merge清理旧数据
什么时候进行Segment合并
- 后台自动合并
- Flush时触发
- 手动触发
- 基于segment数量和大小(数量/存储大小达到阈值
Lucene
倒排索引
FST
https://juejin.cn/post/7226710109585424440
FST(有限状态机)用于快速检索、前缀匹配、范围查询
ES中主要用于存储 词典
为什么要使用FST?
- 倒排索引中词典十分庞大,需要通过关键字快速定位Posting List
- 兼顾 小空间占用 + 快速查询
FST的结构和组织方式
可以理解为压缩版的有向图(共享前缀和后缀)
核心元素
- 节点: 一个状态,代表某个字符读到这里了
- 边: 从一个节点到另一个节点的跳转,携带一个字符/字符范围
- 输出: 走到某个路径时累加的值
- 所有以该前缀开头的词项的公共信息(如内存地址)-》前缀优化共享
- 权重(如概率、分数),通过累加得到路径总权重。
- 该词在倒排索引中的 文件偏移量(File Pointer)。
- 前缀共享
- 后缀合并
搜索关键词时,怎么使用FST?
通过前缀遍历快速找到关键词,然后拿到Posting List然后拿到文档ID
思考: 前缀遍历?那 apple 构建状态机后, 使用 pl 如何搜索呢?
害,pl 和apple已经是两个单词了,且没有共用一个前缀,所以无法搜到,除非把apple五个字母都进行拆分
实在要搞的话,可以建立反向索引或者使用高级搜索,遍历Segment
如何支持模糊搜索? (这里不同于MySQL的模糊搜索)
比如使用appld 可以搜到apple
- 开始遍历时,记录当前位置和当前误差次数。
- 遇到不同字符时,不是直接失败,而是:
- 如果误差没超上限(比如1次),尝试走插入/删除/替换的可能路径!
- 找到匹配路径后,返回最接近的词
FST和Trie、Hash表的区别,为什么不是Trie?为什么不用Hash
- Trie只能共享前缀,内存消耗较大,每个节点存储一个字符串
- 通过前缀遍历得到的 词组 + 输出值便能得到 该词在倒排索引表中的偏移量,无需是使用Hash定位(甚至不需要解决hash冲突)
- 查找效率更高,无需注意哈希函数计算以及冲突问题
- Hash不关心顺序
- 设计不当时,Hash内存开销更大
FST查询过程,如何快速查询?如何找到一个词的posting list起始位置
- 通过前缀遍历进行匹配
- 若设置了模糊查询可以忍受一定程度的不同(比如app-》ape)
- 走完整个词(比如app 走到 p时,发现该边指向节点接受状态(此时累计的输出值就是posting list的起始位置
积累值会变化
小demo体验一下创建过程
番外?
FST结构(有序!): |
增删改时,FST变化
新增文档
- 每次新增文档时,并不会修改已有 segment 的 FST
- 而是生成一个新的 FST(对应新的 segment)
删除文档时
- Lucene 给对应的 DocID 打上 delete 标记(bitmap)
- Posting list / FST 本身 不变
- 查询阶段跳过已删除 DocID
更新文档时
- 标记旧文档删除(不会动老 FST)
- 插入新文档 -> 写入内存 -> flush 生成新 segment + 新 FST
merge FST会做什么?
- 合并多个 segment(包含它们的倒排表 + FST)
- 去除被删除文档(只保留有效 docID)
- 重建新的倒排索引和一个新的 合并后的 FST
Posting List
用于记录每个分词 出现在哪些文档的id集合
Segment(Import!)
https://github.dev/apache/lucene
Segment |
核心组成部分
- 倒排索引(FST+Posting List)
- 词项字典 (存储所有的 词项 term ,使用 FST 压缩
- 倒排列表(记录 词项 对应的 文档ID 以及位置信息(词频、偏移量)
- 存储词项位置和负载(用于短语查询和高亮
加速全文搜索
- Doc Values
- 存储字段的列式数据(numeric、keyword等)
- 存储元数据(最大值、最小值、压缩方式
加速排序、聚合、脚本计算,按照 列式 存储字段
- 文档存储( 使用正排索引读取 DocId -> _source
用于存储原始文档内容(_source)用于返回搜索结果
存储原始JSON文档
存储文档的元信息(偏移量、压缩方式
- 文档ID映射 (DocID -> _id)
内部简历DocID 和用户 _id的映射关系
Segment的元信息,DocID 范围
_id 通过倒排索引与 DocID 关联
DocID 通过正排索引拿到文档
https://github.dev/apache/lucene ———-> codec-> SegmentInfo.java
public final class SegmentInfo { |
BKD树
K-D 树 + B+树混合
- 适用场景:数值过滤、地理围栏、时间区间分析等
- 优势:
- 高效磁盘存储:数据按块(Block)组织,减少随机 I/O。
- 查询优化:剪枝策略快速跳过不匹配的数据块。
- 压缩存储:对数值类型(如整数、浮点数)采用增量编码压缩。
LSM树
https://zhuanlan.zhihu.com/p/181498475
https://zhuanlan.zhihu.com/p/415799237
Memtable
存储在内存中,用于保存最近更新的数据
通常使用红黑树/跳表数据结构实现,按照Key有序地组织这些数据
写入的时候通常会追加一份WAL(Write Ahead log)预写日志,保证宕机恢复
当memtable达到一定大小时,会flush到磁盘中
Immutable memtable
memtable到sstable的一个中间状态
- 当memtable满了之后,不会直接删除,会变为一个只读的immutable memetable
- 同时创建一个新的memtable用来接收写请求
- 这个immutable memtable会通过后台线程刷盘,变为sstable
为什么这么设计?
- 写操作不中断
- 异步刷盘
SSTable
- 当Immutable memeTable刷盘到磁盘中,形成一个SSTable文件
- 由于是顺序写到磁盘,写性能极高
- SSTable是不可变的,只能增加或者合并产生新的SSTable
主要包含内容
- Key/value数据(有序
- 稀疏索引(快速定位
- 布隆过滤器(快速判断key是否存在
- 元数据(校验数据,时间戳等–》因为可能存在重复key,更新时间最新的才是有效key
Compact策略
- Size-tiered 策略
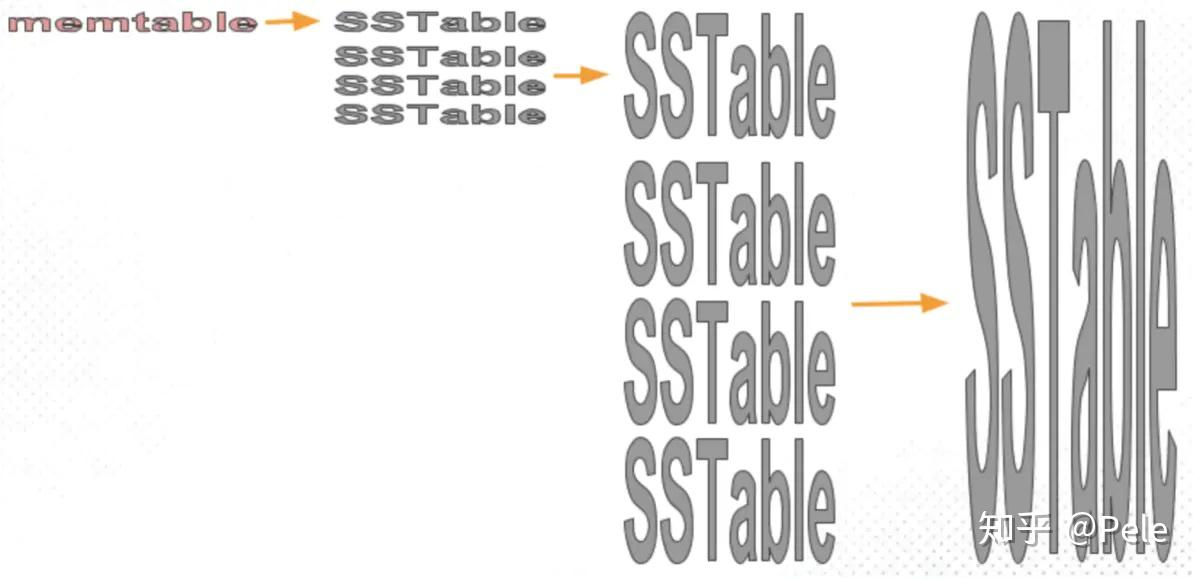
- Leveled 策略
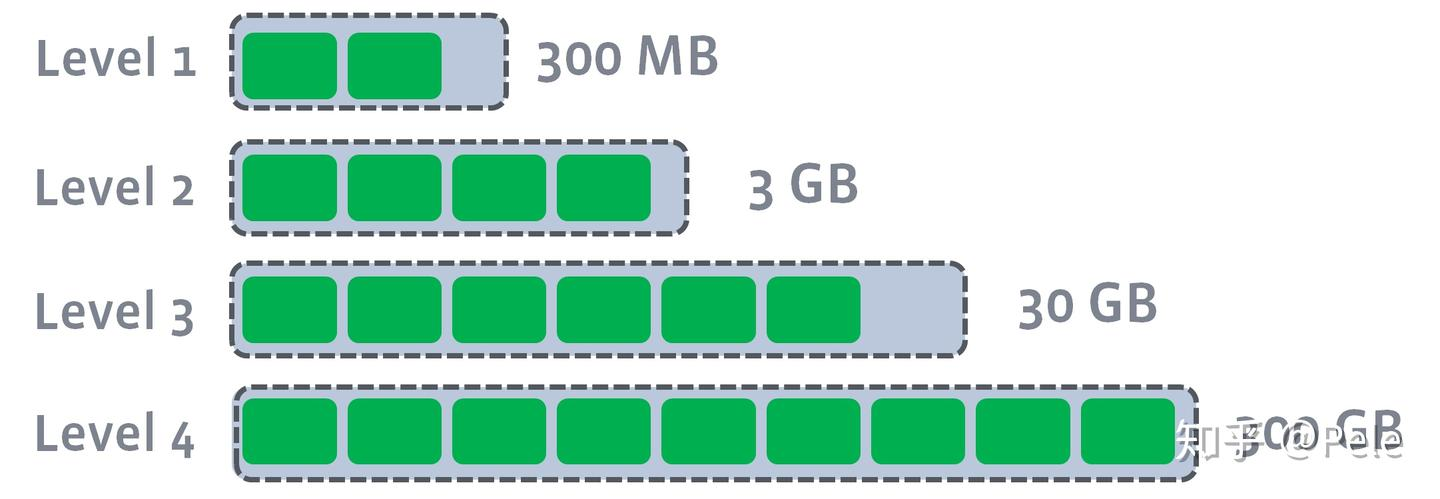
关键点:
- 读放大
- 写放大
- 空间放大
Level 0: 刚flush出来的小sstable文件,不要求有序,且key之间范围可以重叠
Leve 1 及以上: 每一层文件的key范围不重叠,数据量更大
增删查改操作
插入操作
由于LSM树初衷就是应对写操作极为频繁的场景
插入操作只需要无脑写入memtable就行了
删除操作
采用逻辑删除
写一条墓碑标记到 WAL 和 memtable中
真正删除该数据是在compaction时完成
也就是说物理数据在memtable中还是磁盘中,还是不存在,无需关系
compaction过程会进行删除
查询操作
- 先查memtable(因为是最新的操作)
- 再查immutable memtable
- 还没有找到则按照level 0 - n依次查找
- 查询时要处理墓碑标记(如果找到墓碑,就算有旧数据,也算被删除)
- 随着level越高,文件越少、范围越大(减少查找代价)
更新操作
- 写入WAL
- 写入memtable
- 待修改数据在memtable中,直接覆盖
- 带修改数据在磁盘中 直接写在memtable中,后续合并时新数据覆盖旧
- 该数据不存在,update操作变为insert
其实update和insert操作在这里貌似就是相同的
有墓碑标记的数据什么时候被清除呢?会不会永远无法清除?
SSTable合并时删除带有墓碑标记的数据
为什么不能马上删除?
由于LSM树的机制,不同层可能包含相同的key
直接删除可能会漏删老版本,或者删除代价极大
解决删除不及时的办法
- 定期强制压缩
- 设置墓碑最大存活时间
- 创建一个新SSTable,然后进行拷贝
ElasticSearch(Lucene) 与LSM的异同
| LSM树 | Lucene(ES) | |
|---|---|---|
| 写入 | 先写WAL文件再写入MemTable | 先写Translog,再写入in-memroy-buffer |
| 刷盘 | MemTable满了刷入immutable 然后刷入sstable | in-mm-buffer满了(或1秒后)刷入Page Cache然后刷入磁盘 |
| 查询 | 先mt,再imt,再sst(读放大严重) | 先内存中的segment、再磁盘中的segment 加入Caching优化机制,优先读最新段 |
| 删除 | 墓碑、懒回收、合并清除 | 墓碑,懒回收,合并清除 |
| 合并 | Compaction | Segment Merge |
| 数据 | LSMKey/value数据(有序稀疏索引(快速定位布隆过滤器(快速判断key是否存在元数据(校验数据,时间戳等–》因为可能存在重复key,更新时间最新的才是有效key | 倒排索引(FST + Posting List)文档存储(JSON) 元数据 |
| 查询优化 | 布隆过滤器、二分查找 | FST词典、跳表、缓存 |
| 数据不可修改 | 是 | 是 |
| 空间回收 | 合并时清理墓碑、去重 | 合并时清理已删除文档 |
| 关注点 | 写多读少(SSTable有序) | 写少读多 |
核心相似点
- 追加写入
- 两者都是先将数据写入到内存中,然后刷盘不可变的文件中
- 通过顺序写入减少随机IO
- 分层合并
- LSM树通过后台合并,将多个SSTable合并为更大更有序的SSTable,更新文件,删除冗余数据(重复key)
- Lucene通过后台合并,将多个小segment合并为一个大Segment,优化查询性能,并回收空间
- 不可变性
- SSTable和Segment写入磁盘后无法更改,删除/更新操作通过追加 + 合并进行实现
- 简化并发控制,避免锁竞争
关键差异
- 设计目标
- 数据结构
- 合并策略
- 删除处理
核心思想
从集群来看ES
集群
Cluster= 一群Node + 一个Master Node(协调)+ 数据分散存储
结点
- Mater Node:复杂管理Cluster状态(建索引、删除、分片分片等)
- Data Node: 负责存储数据、处理读写请求
- Coordinating Node: 负责接收请求、拆分请求、分发到各个结点,最后聚合结果
- Ingest Node: 做预处理
一个结点可以有多个身份
索引
Index相当于数据库中的表,逻辑上的数据集合
- 每个Index物理上会被分成多个 Shard(分片,存储到不同结点上
- 索引创建时就需要指定主分片数+副本分片数
分片
- 主分片(Primary Shard):真正存储数据的分片。
- 副本分片(Replica Shard):主分片的拷贝,用于容灾、高可用,同时也能分担查询负载。
- 每个分片其实内部就是一个 Lucene 引擎实例(独立维护倒排索引、Segment、Document等)。
| 概念 | 描述 |
|---|---|
| Node | 运行中的 Elasticsearch 实例,托管若干个 Shard |
| Shard | 由 Node 托管,实际保存数据和索引(底层用 Lucene 实现) |
| 一个 Node | 可以承载 多个 Shard(包括主分片和副本分片) |
| 一个 Shard | 只能存在于 一个 Node 上(同一个 Shard 不会横跨多个 Node) |
🔥 举个例子
假设:
- 我创建了一个
products索引 - 设置为 3个主分片,每个主分片 1个副本
那就是一共:
- 3 个 Primary Shard(主)
- 3 个 Replica Shard(副本)
- 总计 6 个 Shard
如果你的集群有 3 个 Node,那么可能的分配:
| Node | 托管的分片 |
|---|---|
| Node 1 | Primary 1, Replica 2 |
| Node 2 | Primary 2, Replica 3 |
| Node 3 | Primary 3, Replica 1 |
⚡ 注意:Elasticsearch 调度器会尽量让 主副本和副副本不在同一台机器上,以提高容错性!
番外
. 用 geo_shape 类型(而不是 geo_point)
geo_point:经纬度,单个点(只能做简单的附近搜索)geo_shape:支持复杂的几何图形,比如:Polygon(多边形)、MultiPolygon(多个多边形)、Line、Envelope 等等。
示例:建索引 Mapping:
PUT /stores |
- 存储门店配送范围(多边形Polygon)
每家店上传一个或多个 Polygon:
POST /stores/_doc |
- 这里的
coordinates是经纬度数组(WGS84坐标系)。 - 每个 Polygon 一定要首尾闭合。
- 检索用户位置是否在配送区内
使用 geo_shape 的 intersects 查询:
GET /stores/_search |
- 意思是:找到所有 配送区域覆盖这个点的门店。
- 当然也可以用
within、contains等其他空间关系。
HNSW
todo 这一节更多是会写到RAG&MCP应用文章中,后续放一个跳转链接
场景设计
外卖系统怎么用ES聚合附近商家的评分?
比如,用户打开饿了么,美团,想找附近评价高的商家。
- 商家文档结构(在ES里)
{ |
- 用户搜索流程
- 根据用户位置(比如上海市中心)用 geo_distance 查询,查出 3km 内的商家。
- 然后用 聚合(Aggregation):
- 按评分(
rating)做 平均值、排序,挑评分最高的商家。 - 按销量(
monthly_sales)做 销量榜单。
- 按评分(
具体的 ES 查询
{ |
🛒 电商系统怎么用ES算实时销售榜?
比如淘宝、京东首页上,「实时热销榜」就是这么搞的!
- 商品文档结构(在ES里)
{ |
- 查询实时热销榜流程
- 用字段
last_30min_sales按照销量做 降序排序。 - 只取 Top 100 热销商品。
- 如果按品类分类(比如”手机”、”家电”),再做个 terms aggregation 按 category 分组!
具体的 ES 查询
{ |
如果要按分类出榜单,再加一个聚合:
"aggs": { |
👉 效果:比如“手机”品类下热销前5名,“家电”下热销前5名。
对比Redis的Zset有什么优势?
- 支持复杂筛选:比如「上海地区,手机品类,价格5000以内,近一周销量榜」。
- 支持复杂聚合分析:比如「按品牌分组统计销量」「统计每天销量走势」。
- 支持冷热数据分层:老数据转冷,不影响新数据查询。
- 适合超大规模数据:TB级,PB级也能撑住。





