ElasticSearch的作用
ElasticSearch是一款非常强大的开源搜素引擎,具备非常强大的功能,可以帮助我们从海量数据中快速找到需要的内容
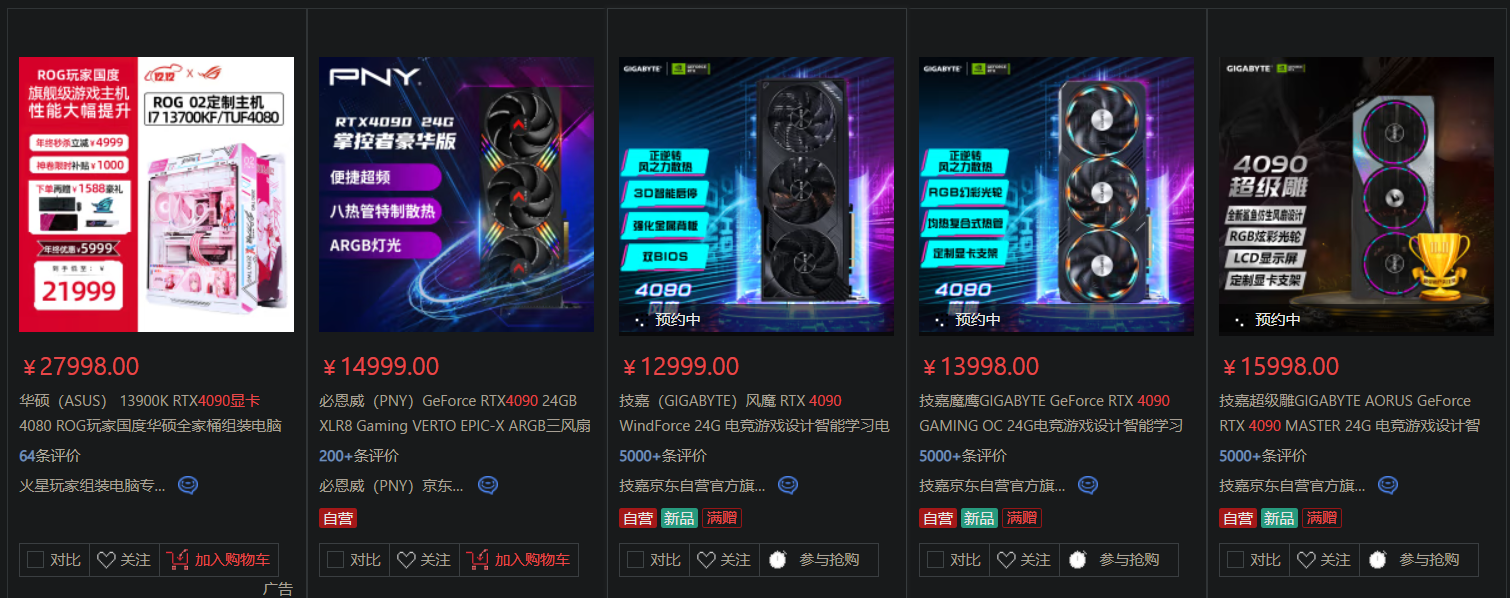
例如在电商平台搜索商品,搜索4090显卡会以红色标识
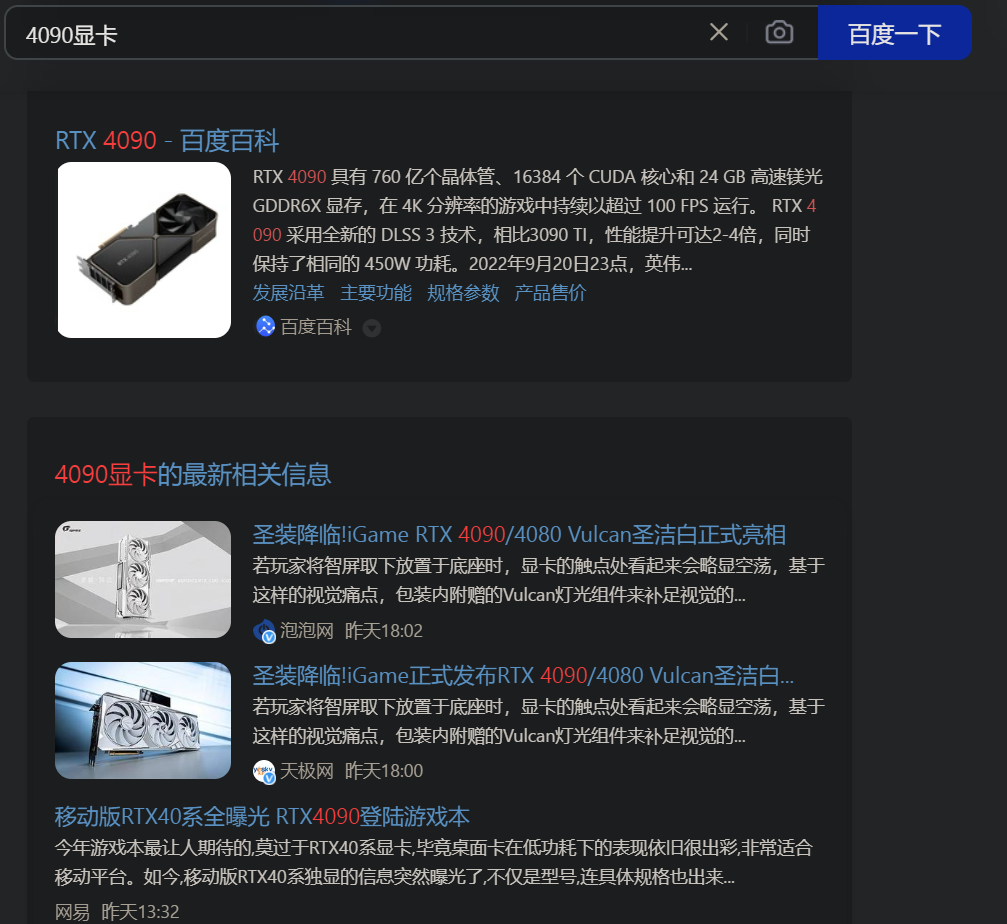
在搜索引擎搜索答案,搜索到的内容同样会以红色标识,也可以实现搜索时的自动补全功能
ELK技术栈
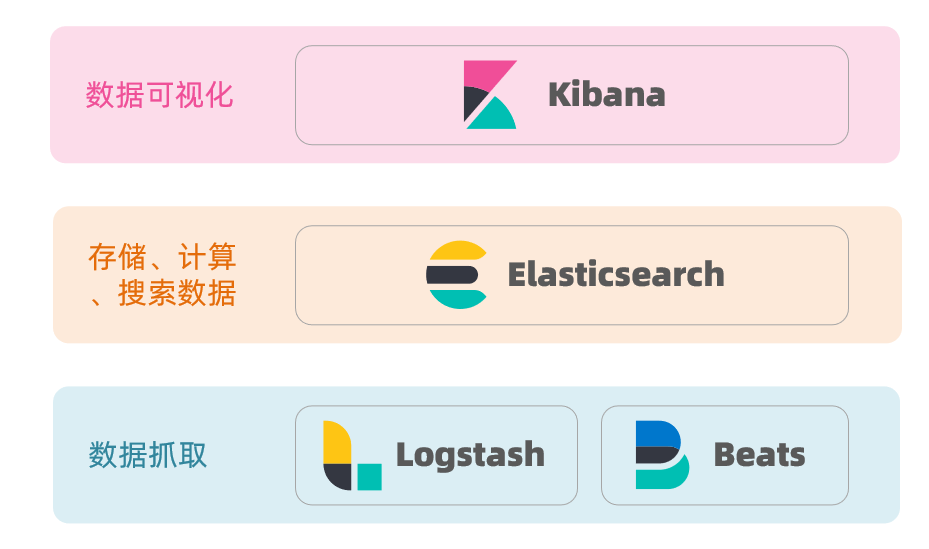
ElasticSearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
- 而
ElasticSearch是elastic stack的核心,负责存储、搜索、分析数据
ElasticSearch和Lucene
- ElasticSearch底层是基于Lucene来实现的
- Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发,官网地址:https://lucene.apache.org/
- Lucene的优势
- Lucene的缺点
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
- ElasticSearch的发展史
- 相比于Lucene,ElasticSearch具备以下优势
- 支持分布式,可水平扩展
- 提供Restful接口,可以被任意语言调用
倒排索引
- 倒排索引的概念是基于MySQL这样的正向索引而言的
正向索引
- 为了搞明白什么是倒排索引,我们先来看看什么是正向索引,例如给下表中的id创建索引
| id |
title |
price |
| 1 |
小米手机 |
3499 |
| 2 |
华为手机 |
4999 |
| 3 |
华为小米充电器 |
49 |
| 4 |
小米手环 |
49 |
- 如果是基于id查询,那么直接走索引,查询速度非常快。
- 但是实际应用里,用户并不知道每一个商品的id,他们只知道title(商品名称),所以对于用户的查询方式,是基于title(商品名称)做模糊查询,只能是逐行扫描数据
SQL
select id, title, price from tb_goods where title like %手机%
|
- 具体流程如下
- 用户搜索数据,搜索框输入手机,那么条件就是title符合
%手机%
- 逐行获取数据
- 判断数据中的title是否符合用户搜索条件
- 如果符合,则放入结果集,不符合则丢弃
- 逐行扫描,也就是全表扫描,随着数据量的增加,其查询效率也会越来越低。当数据量达到百万时,这将是一场灾难
倒排索引
- 倒排索引中有两个非常重要的概念
- 文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我最喜欢的FPS游戏是Apex,就可以分为我、我最喜欢、FPS游戏、最喜欢的FPS、Apex这样的几个词条
- 创建倒排索引是对正向索引的一种特殊处理,流程如下
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
正向索引是最传统的,根据id索引的方式。但是根据词条查询是,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档查找词条的过程- 而
倒排索引则相反,是先找到用户要搜索的词条,然后根据词条得到包含词条的文档id,然后根据文档id获取文档,是根据词条查找文档的过程
那么二者的优缺点各是什么呢?
Elasticsearch核心概念

注意:Elasticsearch约定一个索引只能有一个类型type,并且类型名固定为(_doc)
MySQL与ElasticSearch
- 我们统一的把MySQL和ElasticSearch的概念做一下对比
| MySQL |
Elasticsearch |
说明 |
| Table |
Index |
索引(index),就是文档的集合,类似数据库的表(Table) |
| Row |
Document |
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column |
Field |
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema |
Mapping |
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL |
DSL |
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
二者各有自己擅长之处
MySQL:产长事务类型操作,可以保证数据的安全和一致性ElasticSearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是这二者结合使用
MySQL与ElasticSearch
- 我们统一的把MySQL和ElasticSearch的概念做一下对比
| MySQL |
Elasticsearch |
说明 |
| Table |
Index |
索引(index),就是文档的集合,类似数据库的表(Table) |
| Row |
Document |
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column |
Field |
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema |
Mapping |
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL |
DSL |
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
- 二者各有自己擅长之处
MySQL:产长事务类型操作,可以保证数据的安全和一致性ElasticSearch:擅长海量数据的搜索、分析、计算
- 因此在企业中,往往是这二者结合使用
- 对安全性要求较高的写操作,使用MySQL实现
- 对查询性能个较高的搜索需求,使用ElasticSearch实现
- 二者再基于某种方式,实现数据的同步,保证一致性
Docker部署单点ES
- 因为我们还需要部署Kibana(可视化)容器,因此需要让他们处于同一个网络,为了方便使用名字查询,所以不使用默认的匿名网络。(使用compose部署可以一键互联,不需要这个步骤,但是将来有可能不需要kbiana,只需要es,所以先这里手动部署单点es)
docker network create es-net
|
docker pull elasticsearch:7.17.9
//注意版本,此后安装kibana以及ik分词器等都需要版本一致
|
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
elasticsearch:7.17.9
|
- 命令解释:
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":配置JVM的堆内存大小,默认是1G,但是最好不要低于512M-e "discovery.type=single-node":单点部署-v es-data:/usr/share/elasticsearch/data:数据卷挂载,绑定es的数据目录-v es-plugins:/usr/share/elasticsearch/plugins:数据卷挂载,绑定es的插件目录-privileged:授予逻辑卷访问权--network es-net:让ES加入到这个网络当中-p 9200:暴露的HTTP协议端口,供我们用户访问的
启动成功后打开192.168.87.132:9200(这里是我的虚拟机ip)
部署kibana
docker pull kibana:7.17.9
|
运行docker命令
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--net work=es-net \
-p 5601:5601 \
kibana:7.17.9
|
- 命令解释
--network=es-net:让kibana加入es-net这个网络,与ES在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200:设置ES的地址,因为kibana和ES在同一个网络,因此可以直接用容器名访问ES-p 5601:5601:端口映射配置
成功启动后,打开浏览器访问:192.168.87.132:5601,即可以看到结果
安装ik分词器
docker exec -it elasticsearch /bin/bash
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.9/elasticsearch-analysis-ik-7.17.9.zip
exit
docker restart elasticsearch
|
- IK分词器包含两种模式
ik_smart:最少切分ik_max_word:最细切分
随着互联网的发展,造词运动也愈发频繁。出现了许多新词汇,但是在原有的词汇表中并不存在,例如白给、白嫖等
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能
- 打开IK分词器的config目录
- 找到IKAnalyzer.cfg.xml文件,并添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_dict">ext.dic</entry>
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
|
在IKAnalyzer.cfg.xml同级目录下新建ext.dic和stopword.dic,并编辑内容
索引库操作
- 索引库就类似于数据库表,mapping映射就类似表的结构
- 我们要向es中存储数据,必须先创建
库和表
mapping映射属性
CRUD
创建索引库和映射
- 基本语法
- 请求方式:
PUT
- 请求路径:
/{索引库名},可以自定义
- 请求参数:
mapping映射
PUT /{索引库名}
{
"mappings": {
"properties": {
"字段名1": {
"type": "text ",
"analyzer": "standard"
},
"字段名2": {
"type": "text",
"index": true
},
"字段名3": {
"type": "text",
"properties": {
"子字段1": {
"type": "keyword"
},
"子字段2": {
"type": "keyword"
}
}
}
}
}
}
|
PUT /test001
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
|
查询索引库
- 基本语法
- 请求方式:
GET
- 请求路径:
/{索引库名}
- 请求参数:
无
- 格式:
修改索引库
- 基本语法
- 请求方式:
PUT
- 请求路径:
/{索引库名}/_mapping
- 请求参数:
mapping映射
- 格式:
JSON
PUT /{索引库名}/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
|
- 倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库
一旦创建,就无法修改mapping
- 虽然无法修改mapping中已有的字段,但是却允许添加新字段到mapping中,因为不会对倒排索引产生影响
删除索引库
- 基本语法:
- 请求方式:
DELETE
- 请求路径:
/{索引库名}
- 请求参数:无
- 格式
文档操作
新增文档
JSON
POST /{索引库名}/_doc/{文档id}
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}
|
JSON
POST /test001/_doc/1
{
"info": "次元游记兵--恶灵",
"email": "wraith@Apex.net",
"name": {
"firstName": "雷尼",
"lastName": "布莱希"
}
}
|
查询文档
- 根据rest风格,新增是post,查询应该是get,而且一般查询都需要条件,这里我们把文档id带上
- 语法
JSON
GET /{索引库名}/_doc/{id}
|
删除文档
- 删除使用DELETE请求,同样,需要根据id进行删除
- 语法
JSON
DELETE /{索引库名}/_doc/{id}
|
- 示例:根据id删除数据, 若删除的文档不存在, 则result为not found
JSON
DELETE /test001/_doc/1
|
修改文档
- 修改有两种方式
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
全量修改
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了
PUT /{索引库名}/_doc/{文档id}
{
"字段1": "值1",
"字段2": "值2",
}
|
增量修改
JSON
POST /{索引库名}/_update/{文档id}
{
"doc": {
"字段名": "新的值",
...
}
}
|
总结
文档的操作有哪些?
- 创建文档:POST /{索引库名}/_doc/{id}
- 查询文档:GET /{索引库名}/_doc/{id}
- 删除文档:DELETE /{索引库名}/_doc/{id}
- 修改文档
- 全量修改:PUT /{索引库名}/_doc/{id}
- 增量修改:POST /{索引库名}/_update/{id}
Springdata ->JAVA
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
|
spring.elasticsearch.rest.uris=http://localhost:9200
|
@Data
@Document(indexName="product")
public class Product {
@Id
private String id;
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String title;
private Integer price;
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String intro;
@Field(type=FieldType.Keyword)
private String brand;
}
|
这里的index对应Es中的索引。
测试实践
这些简单的curd看看就行
public interface ProductRepository extends ElasticsearchRepository<Product,String> {
}
|
@Service
public class ProductServiceImpl implements IProductService{
@Resource
private ProductRepository repository;
@Resource
private ElasticsearchRestTemplate template;
@Override
public void save(Product product) {
repository.save(product);
}
@Override
public void update(Product product) {
repository.save(product);
}
@Override
public void delete(String id) {
repository.deleteById(id);
}
@Override
public Product get(String id) {
return repository.findById(id).get();
}
@Override
public List<Product> list() {
Iterable<Product> all = repository.findAll();
List<Product>list=new ArrayList<>();
all.forEach(list::add);
return list;
}
}
|
复杂查询以及高亮展示
@Test
public void searchByEs(){
MultiMatchQueryBuilder queryBuilder=QueryBuilders.multiMatchQuery("手机","title", "intro");
queryBuilder.minimumShouldMatch(String.valueOf(1));
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("*");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
highlightBuilder.fragmentSize(699999);
highlightBuilder.numOfFragments(0);
Pageable pageable=PageRequest.of(0,10);
NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withPageable(pageable)
.withHighlightBuilder(highlightBuilder)
.build();
SearchHits<Product> searchHits= template.search(searchQuery, Product.class);
List<Product>list=new ArrayList<>();
if(searchHits.hasSearchHits()){
List<SearchHit<Product>> searchHitList= searchHits.getSearchHits();
for (SearchHit<Product> hit : searchHitList) {
Product product=new Product();
product.setId(hit.getId());
if(hit.getHighlightFields().get("title")!=null){
String title = String.valueOf(hit.getHighlightFields().get("title"));
product.setTitle(title.substring(1,title.length()-1));
}if(hit.getHighlightFields().get("intro")!=null){
String intro=String.valueOf(hit.getHighlightFields().get("intro"));
product.setIntro(intro.substring(1,intro.length()-1));
}
list.add(product);
}
}
list.forEach(System.out::println);
}
}
|



